本文共 2012 字,大约阅读时间需要 6 分钟。
介绍
简介
logstash 是一个数据收集处理引擎。
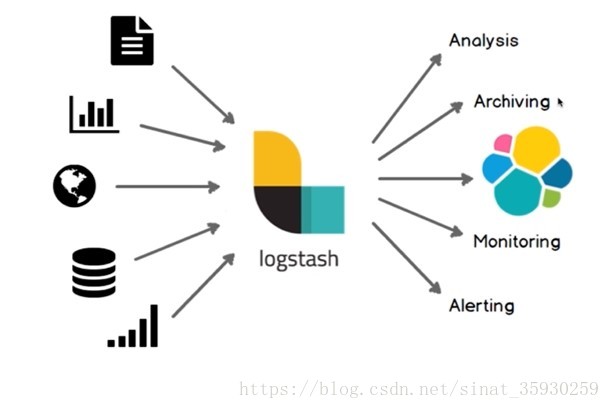
工作流程
分为三个阶段
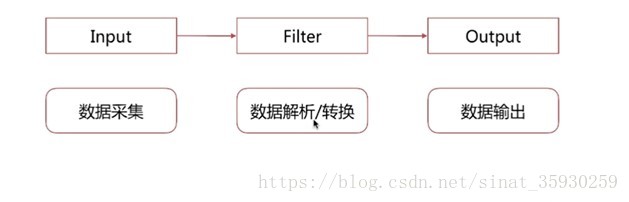
处理流
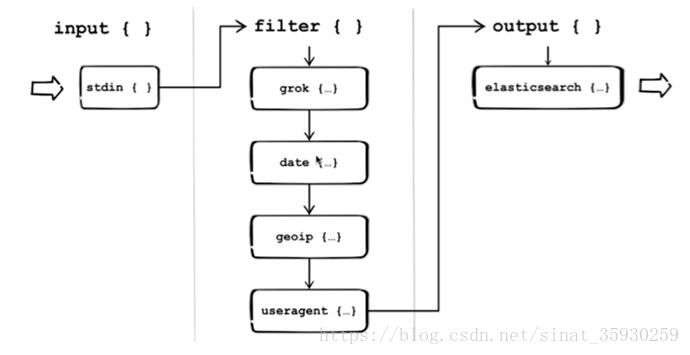
pipeline
pipeline 是input-filter-output的三个阶段的处理流程,包含队列管理、插件生命周期管理。
logstash event
原始数据进入logstash后在内部流转并不是以原始数据的形式流转,在input处被转换为event,在output event处被转换为目标格式的数据。可在配置文件中对其进行增删改查操作。

logstash配置文件示例

将标准输入通过codec转换成line,filter这里为空即不做处理,然后在输出部分经过codec转换成json输出到标准输出。
其数据转换过程如下:
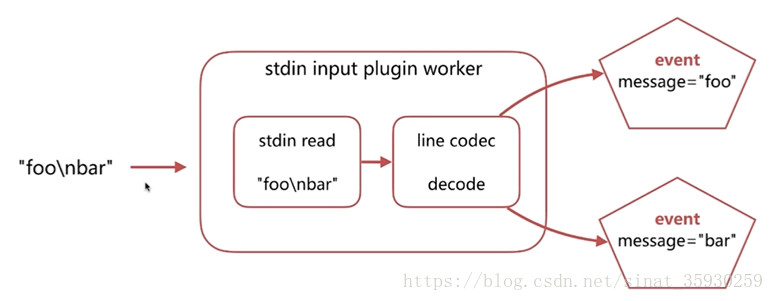

通过下面的命令可以查看执行效果:
echo -e "foo\nbar" | ./bin/logstash -f codec.conf

logstash6.x架构
架构图

箭头代表数据流向。可以有多个input。中间的queue负责将数据分发到不通的pipline中,每个pipline由batcher,filter和output构成。batcher的作用是批量从queue中取数据(可配置)。
logstash数据流历程
首先有一个输入数据,例如是一个web.log文件,其中每一行都是一条数据。file imput会从文件中取出数据,然后通过json codec将数据转换成logstash event。
这条event会通过queue流入某一条pipline处理线程中,首先会存放在batcher中。当batcher达到处理数据的条件(如一定时间或event一定规模)后,batcher会把数据发送到filter中,filter对event数据进行处理后转到output,output就把数据输出到指定的输出位置。
输出后还会返回ACK给queue,包含已经处理的event,queue会将已处理的event进行标记。
queue
queue分类
In Memory
在内存中,固定大小,无法处理进程crash、机器宕机等情况,会导致数据丢失。Persistent Queue In Disk
可处理进程crash情况,保证数据不丢失。保证数据至少消费一次;充当缓冲区,可代替kafka等消息队列作用。
Persistent Queue(PQ)处理流程
1、一条数据经由input进入PQ,PQ将数据备份在disk,然后PQ响应input表示已收到数据;
2、数据从PQ到达filter/output,其处理到事件后返回ACK到PQ; 3、PQ收到ACK后删除磁盘的备份数据;性能对比
PQ性能要低于内存中的queue的,但是差别不是很大。如果不是特殊需求建议打开PQ。

PQ配置
queue.type: persisted
默认是memory,表示使用内存队列
queue.max_bytes: 4gb
队列存储的最大数据量,默认1gb,这个值大一点队列可以存储多一点数据。
线程

在对logstash进行调优的时候主要是调整线程数,主要是pipeline的线程数,它是主要处理数据的线程。
pipeline线程相关配置
pipeline.workers: 2
pipeline线程数,即filter_output的处理线程数,默认为CPU核数。命令行参数为-w
pipeline.batch.size: 125
batcher一次批量获取的待处理文档数,默认125,越大会占据越多的heap空间,可通过jvm.options调整。命令行参数-b
pipeline.batch.delay: 5
batcher等待时长,默认5ms。命令行参数-u
logstash相关配置
logstash设置相关配置文件
logstash设置相关配置文件主要位于conf配置文件下,在logstash启动时使用。
logstash.yml
logstash相关配置,如node.name,path.data等。其中这些配置的参数可以被命令行参数覆盖。jvm.options
jvm相关参数,比如heap、size等。
pipeline配置文件
定义数据处理流程的文件,一般是用户自定义,以.conf结尾。
logstash.yml常见配置项


logstash命令行配置

logstash多实例运行
运行方式

pipeline配置
pipeline用于配置input、filter、output插件,框架如下:

配置语法
数值类型


注释

引用logstash event的属性(字段)
在配置中可以引用logstash event的属性(字段),方式如下:
1、直接引用字段 2、在字符串中以sprintf方式引用

条件判断
支持条件判断语法,从而扩展了配置的多样性

其中表达式操作符如下:

配置示例:
